What would be cool is to be able to track faces and crop around faces. Is that possible through shotstack API or using some other api?
That would indeed be a great capability. What would you use it for?
Shotstack doesn’t provide this, but Google does have an API that gives you back the coordinates of faces per frame.
I currently edit youtube videos to create instagram style shorts using shot stack. In most cases, the speaker is at the center of the screen so it is easier to crop at centre. But given the speaker can be anywhere on screen, for some videos it becomes difficult.
Also in some videos there can be more than one speaker - so it would be useful to know how many faces are there in a video and crop accordingly.
Do you have suggestions on how I can use the coordinates from google API in shotstack to position the video cropping around a face?
Try this: https://www.bigroom.tv/
Unless that has an API like shotstack, this is not really helpful! Sorry
I’m building something similar, its not very easy because of so many edge cases. For example, not only would you want to do face detection, but you would need to do speaker detection so that you can focus on who is talking. In addition, if there no people on the screen, then you would need to decide how to crop.
Cloudinary provides face detection or prominent object detection very easily. The problem however seems to be speaker detection as you rightly pointed out.
I am building similar web app where user inputs a podcast video file and get cropped resized shorts of highlighted clips. Faced same problem of detecting faces and finding out speaking face. For that I used aws rekognition it returns location (width, height, left, top) of faces along with emotions and mouth open confidence value from still image input. From these values we can find out which face is speaking. Its not perfect but works 85% of time. Next challenge is to crop, offset and resizing with shotstack based on the face location from rekognition so we can get speaking person in center of frame e.g in 9:16 aspect ratio. This is where I am struggling. Let me know if any of you have much experience in cropping and resizing with shotstack I would love to share my expertise of aws rekognition
Do you have an example Rekognition output? I would be interested to take a look and see how this could be done or at least offer some pointers.
1 Like
Thank you lucas.spielberg for helping. Yes sure here is a face location example of output from Rekognition:
Height: 0.18882378935813904 (height of face)
Left: 0.22901955246925354 (distance of face from left side of frame)
Top: 0.38813459873199463 (distance of face from top side of frame)
Width: 0.0730341449379921 (height of face)
(all these values are always between 0 and 1)
Basically it replies with array of all faces data in a frame. Each face data consist of location (Height,Left,Top,Width) and other properties like emotions etc From which I am filtering out the speaking face by emotions and mouth open percentage property.
Here is the input frame at the starting time of clip from where trimming should start:

In this scene person on left is speaking so I get LEFT value 0.229 and for right face I get value of LEFT around 0.75
Here is what I want to achieve with shotstack:
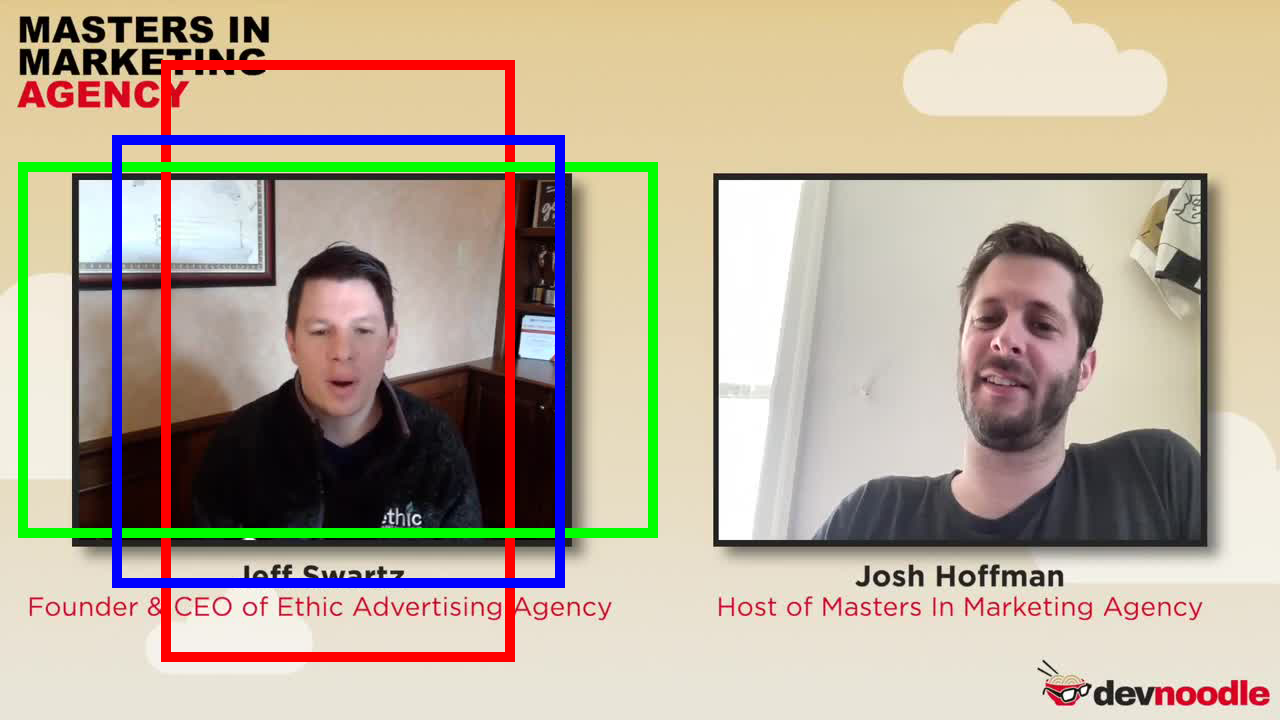
(RED = 9:16, BLUE = 1:1, GREEN= 16:9)
I want to trim and crop (red, blue or green depends on user’s choice) and resize. I understand the resizing and trimming bit but centering the face in clip is where I am stuck. Currently, I am using offsetX and offsetY with the Scale adjustment to achieve this but its not always perfectly centering the face as it gets complicated to calculate with the face location values. In this scene it looks simple but to make the algorithm completely dynamic for any kind of clip (like a scene where face location is in corners or very small or very zoomed in etc) is getting very challenging. I tried using Crop with shotstack but it leaves some black areas on some sides of clip.
IMO it would be much easier to crop and resize outside of shotstack. I don’t know what your stack is like, but this part is relatively simple with python and moviepy. You can even ask chatgpt to write the code for you ![]()
Also, I have used Google’s API which seems similar to Amazon’s, but found the ‘person detection’ to be more useful than face detection, as it will return a bounding box of a person, and the face is usually roughly in the the center.
The problem is less about detecting a person that detecting the one who is currently talking. Does Google allow that?
Similarly to what @fullstackdev mentioned, using mouth/emotion works usually, but isnt perfect. You would need to also use speaker diarization / classification for it to be really robust. Even then, you have scenes with no speaker that would need to be dealt with.
@drfalken you are probably right it should be simple task. But I already got digged too deep in the setup and don’t want to try any alternative ![]() . I am using MERN stack and using shotstack for trimming, subtitles, watermarks, storage etc everything is working as it should be except centering face issue.
. I am using MERN stack and using shotstack for trimming, subtitles, watermarks, storage etc everything is working as it should be except centering face issue.
1 Like
@kamskans I have looked for speaking face detection a lot. Unfortunately, all face detection api’s return similar data. That is face location, emotions, eyes open/close, mouth open/close and objects on face (glasses etc) but no speaking detection was available in any of them may be some open source library helps if tunned accordingly